SQLCache 快速入门
准备工作
添加 flink 生态 (建议都使用kube部署)
- kafkasimple集群
- flinks集群
- dlink服务
- 实时计算平台(必须在dlink服务之后启动)
- 事件中心 (配置好kafka类型)
添加SQL缓存服务并进行相关配置
SQL缓存服务添加
门户开启 DBProxy SQL缓存开关
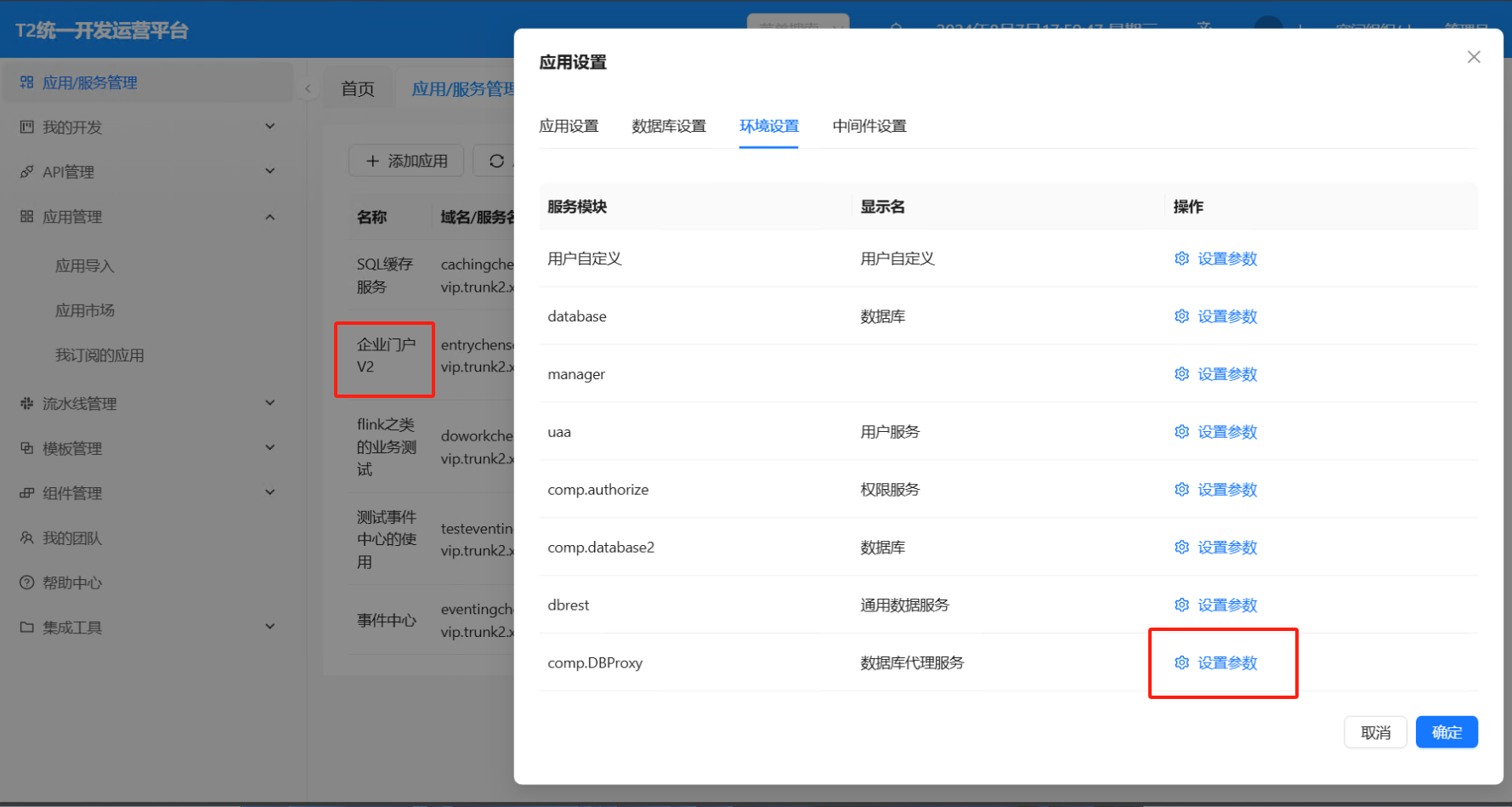
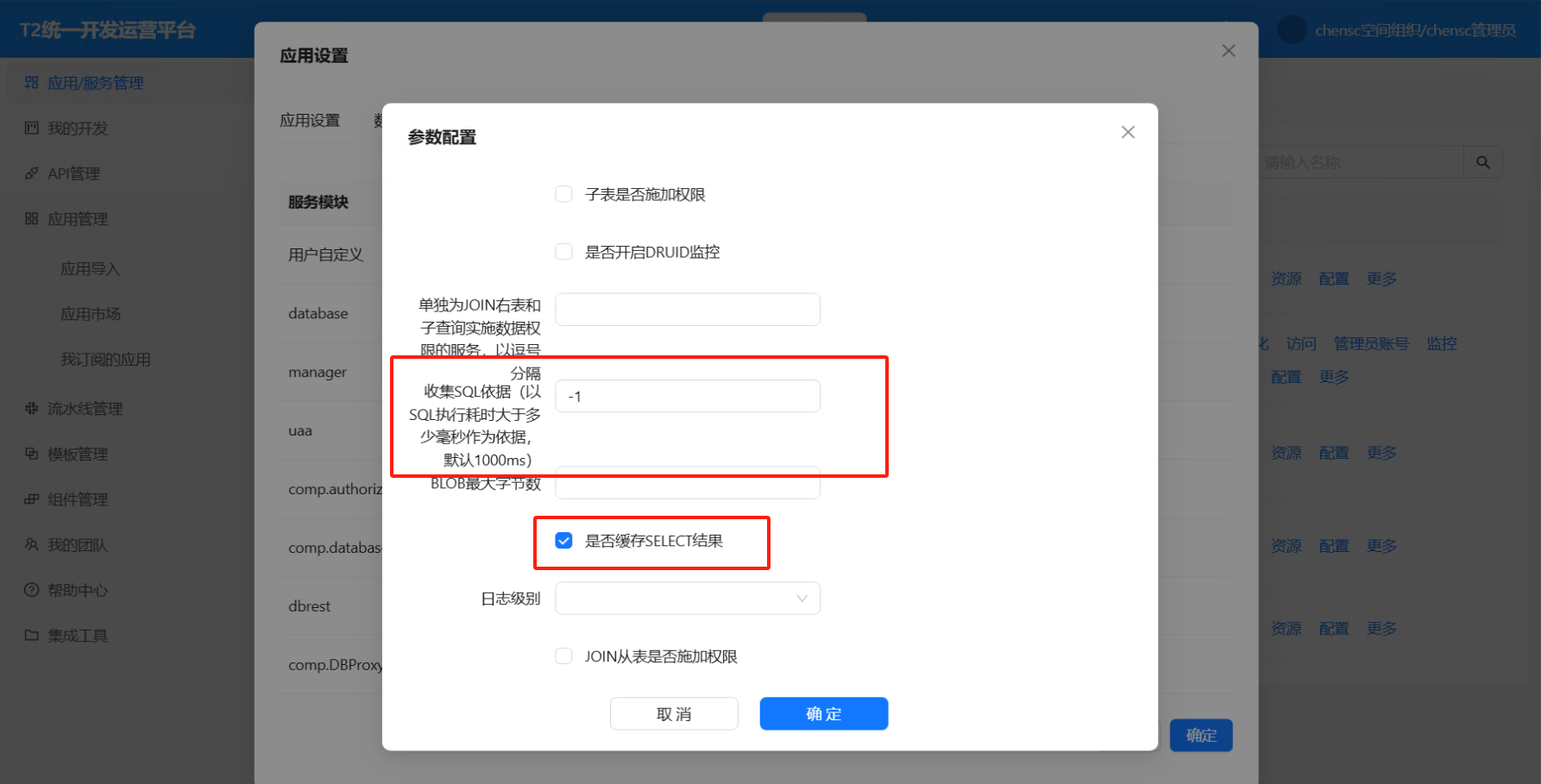
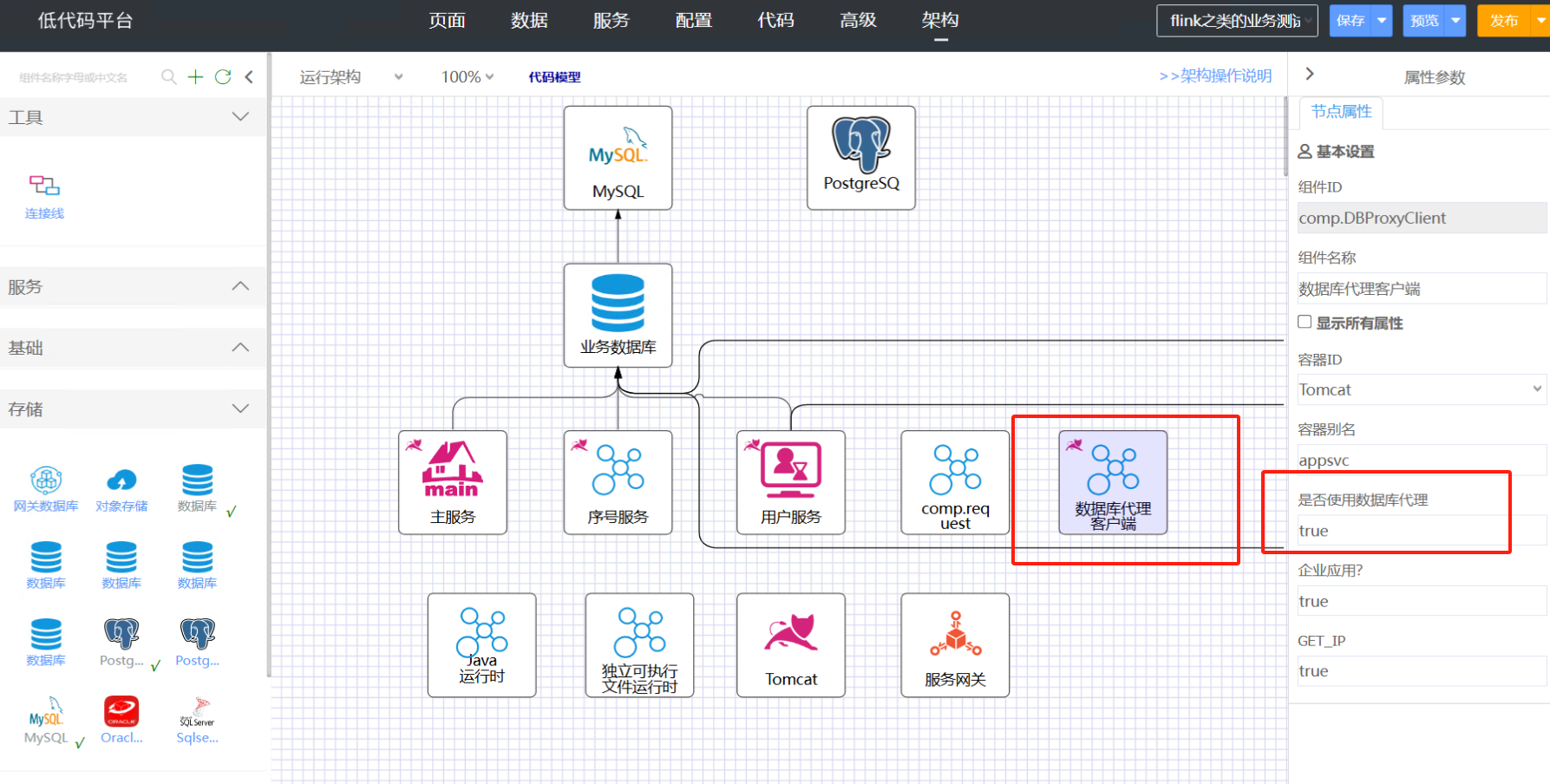
开发应用时 ide 内必须开启数据库代理
SQL收集规则使用和注意事项
SQL收集规则配置服务名、库名、模式名、表名即可收集到对应的SQL,可在SQL缓存管理页面处查看。有些特殊情况需要排除where条件的也可以配置过滤条件。


配置好SQL收集规则后必须进行发布才能生效。

SQL缓存管理使用和注意事项
收集好的SQL记录上只需要勾选缓存,等待一分钟后,当测试按钮变绿,即可使用缓存特性。
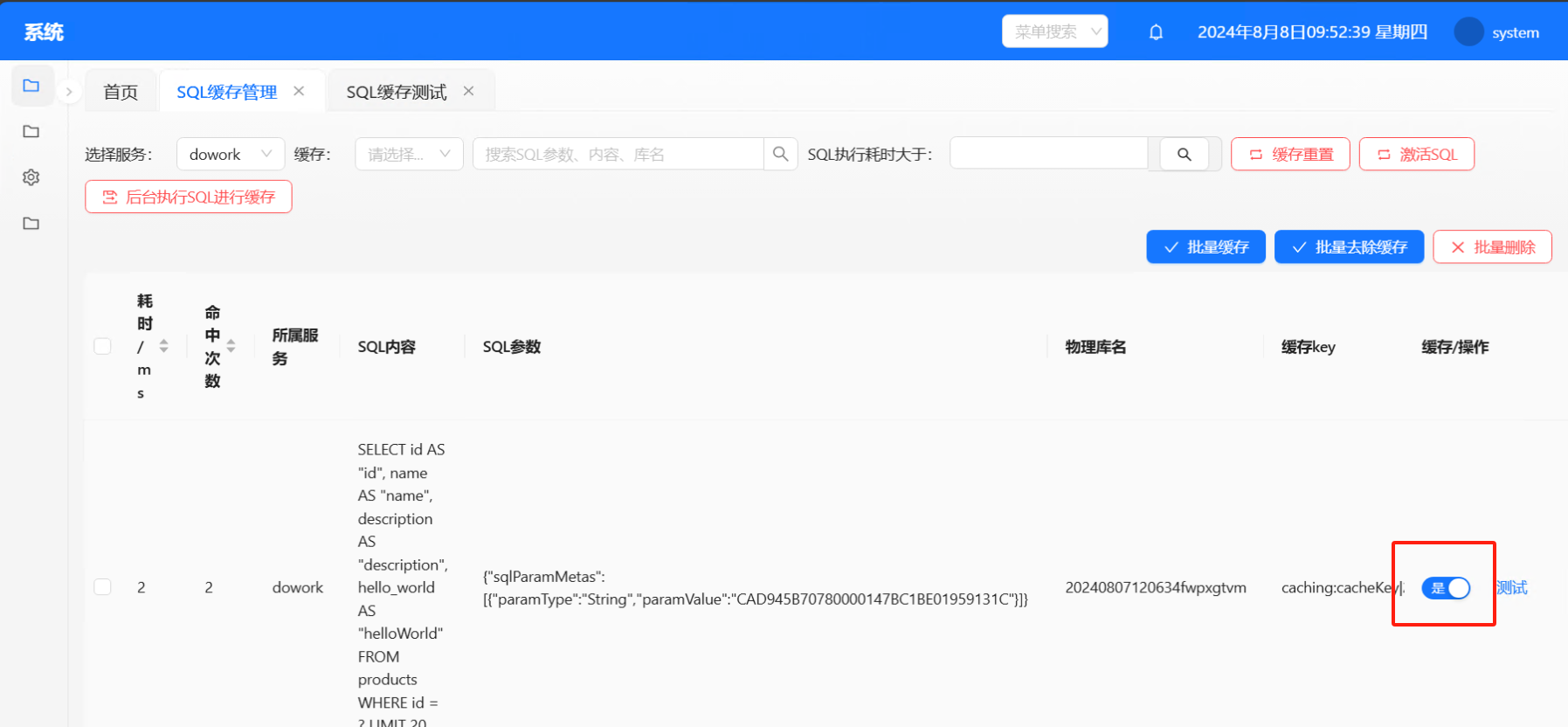
激活SQL:后台有执行激活SQL的定时任务,会每隔1分钟定时执行一次,目的是对勾选缓存的SQL进行SQL分析,生成对应的缓存Key、刷新Key、event-trigger-cdc,和收集SQL时辅助使用到的Key,和命中次数刷库。
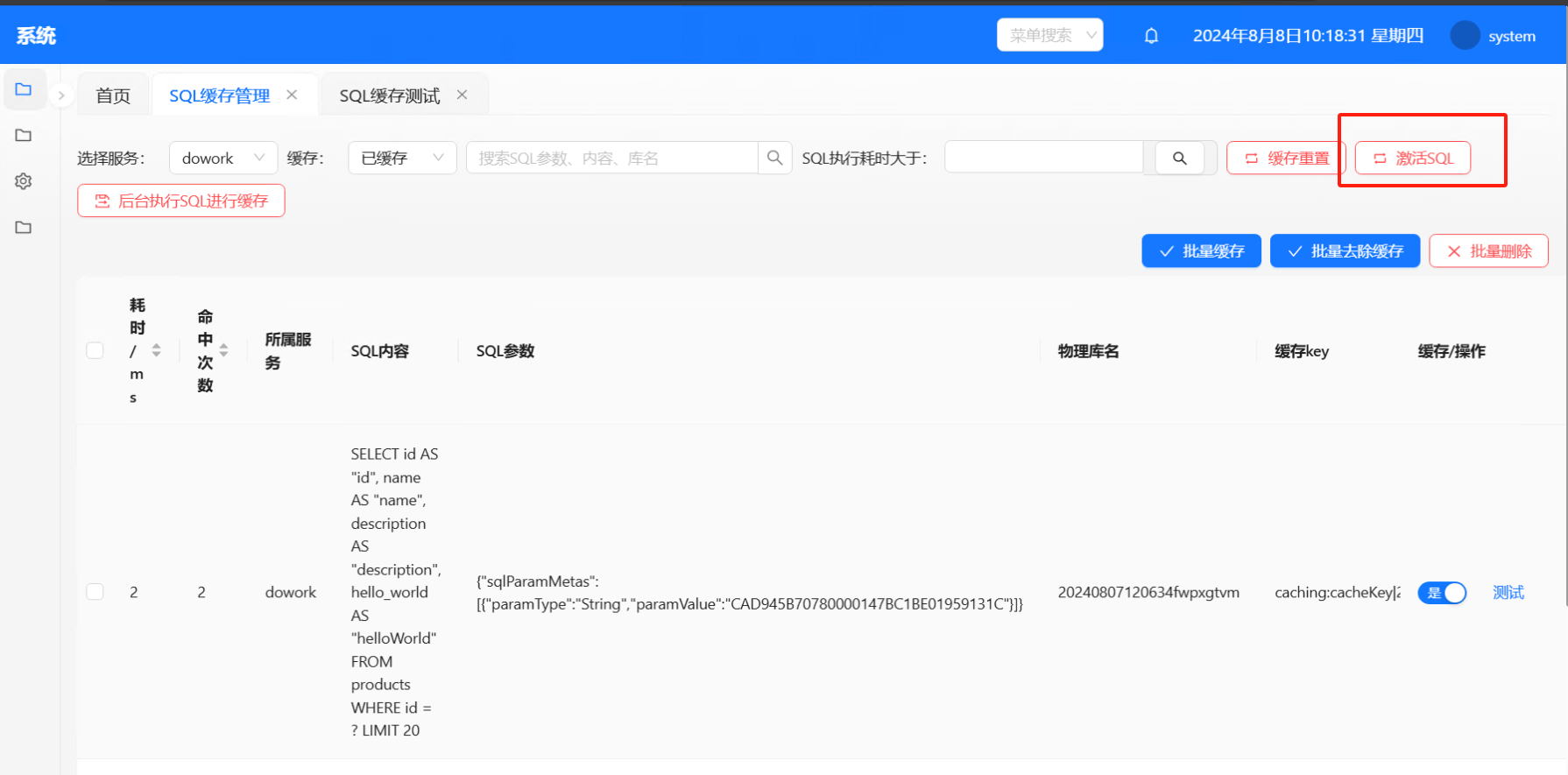
缓存重置:清理缓存Key、刷新Key、event-trigger-cdc、SQL Key、垃圾SQL,目的是恢复到激活SQL之前的初始化状态。
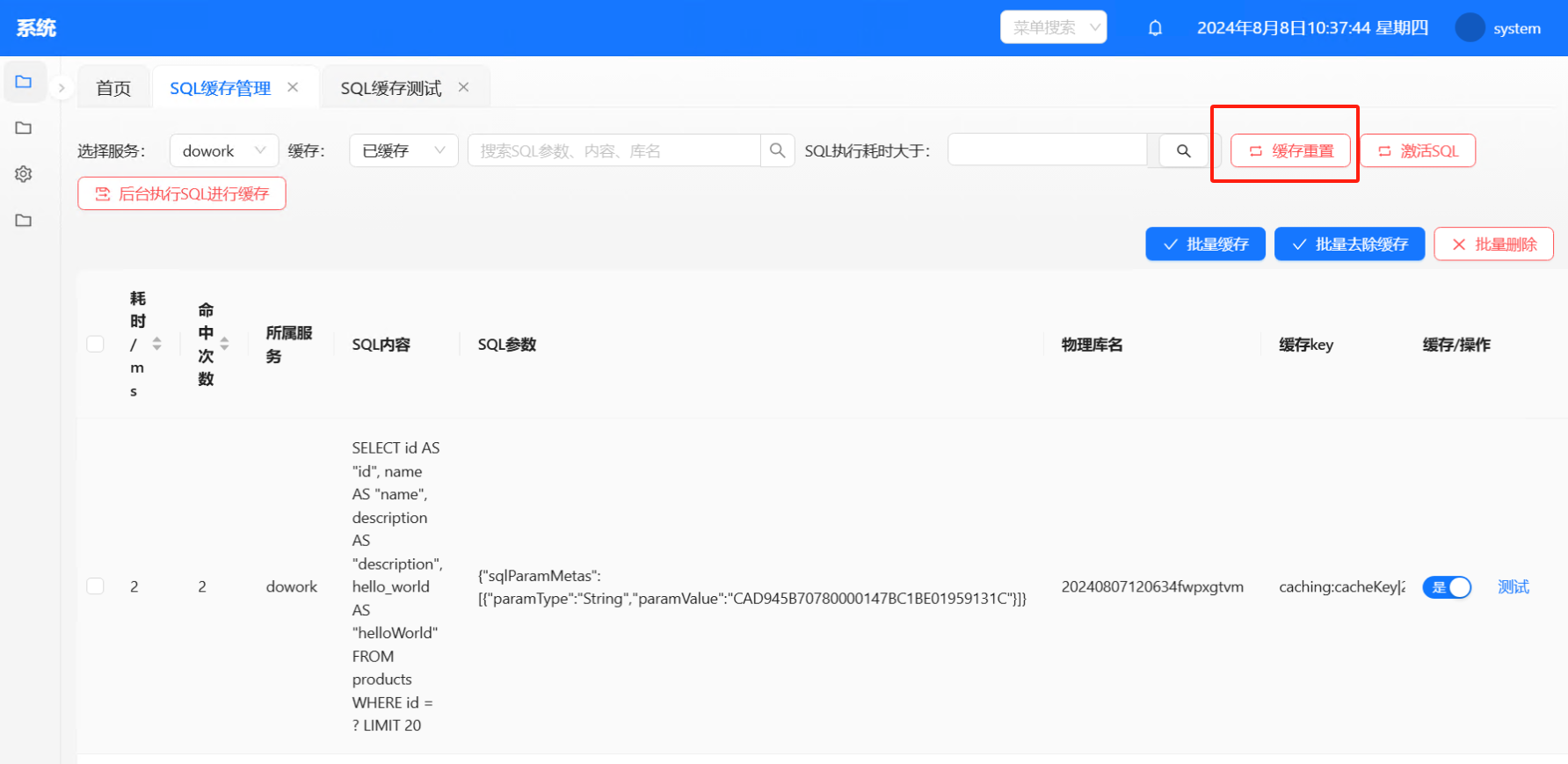
后台执行SQL进行缓存:有后台定时任务,会定时每天凌晨2点执行一次,原理——》以队列的形式批量对勾选缓存的SQL进行执行,将结果覆盖到对应缓存Key上。这样即可以实现预先缓存的效果,大大减轻了缓存击穿和缓存刷新异常所带来的后果。
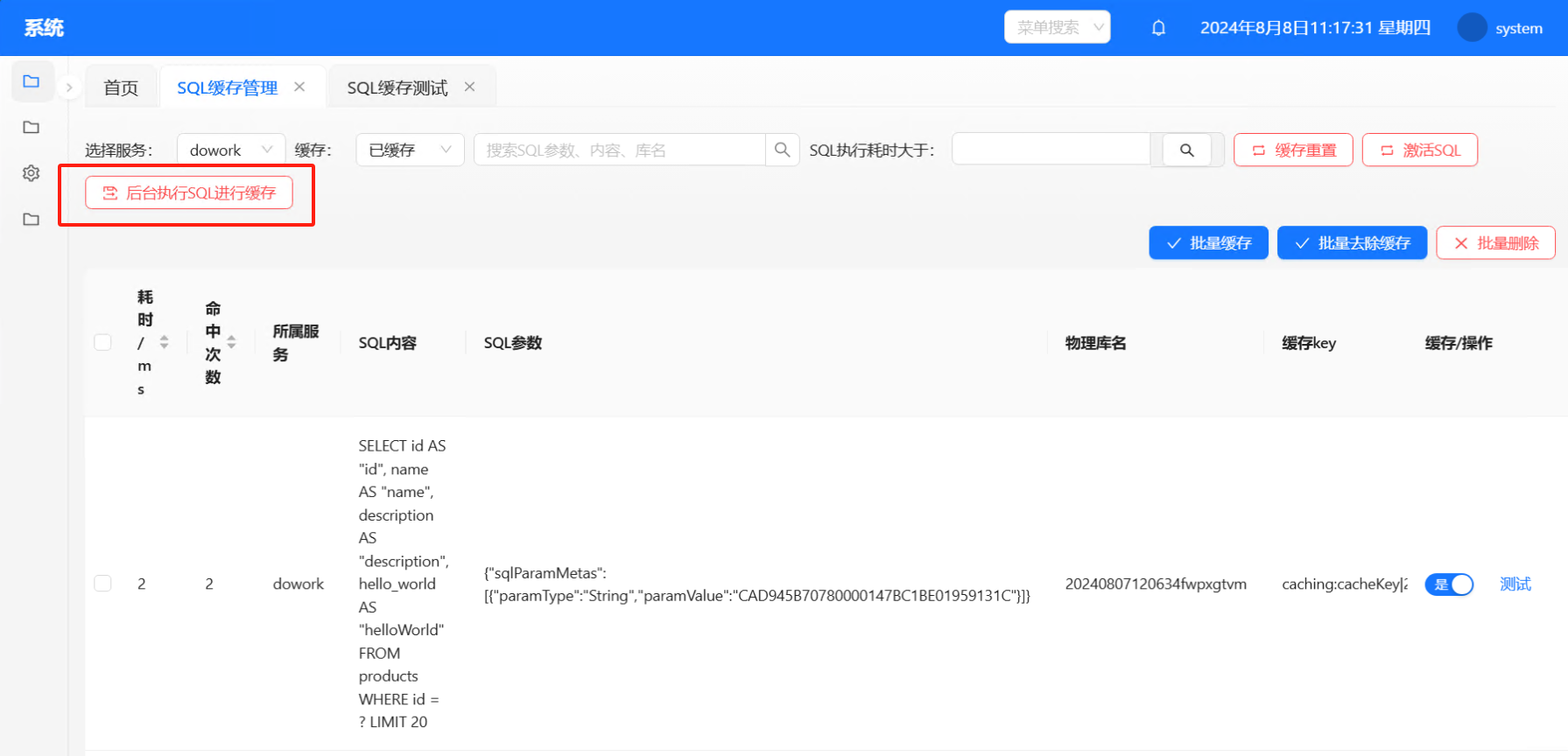
SQL缓存测试:SQL管理页上点击测试即可跳转到SQL缓存测试页,测试页有以下几个功能和注意点
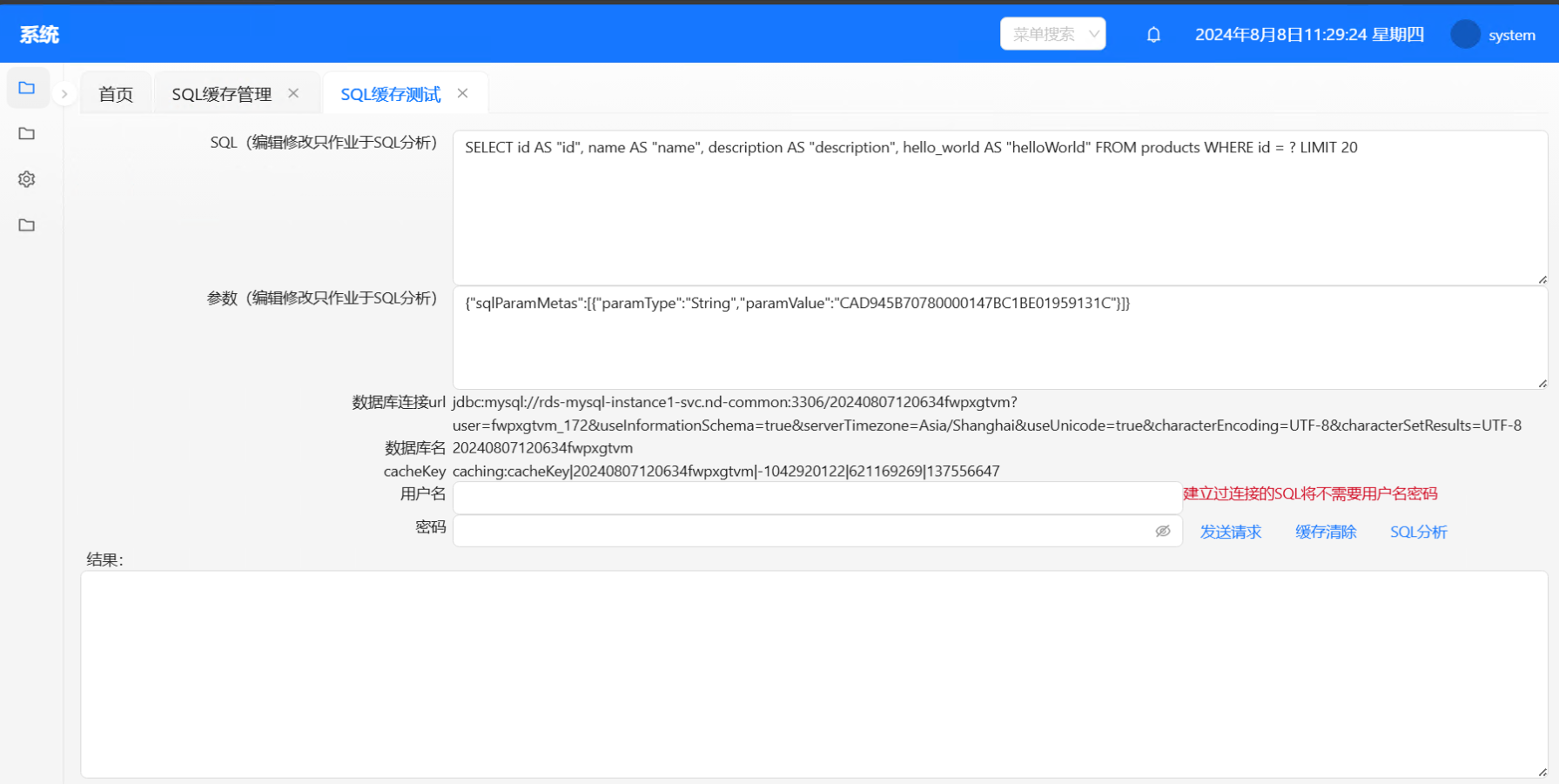
- 发送请求:根据cacheKey获取缓存,如果缓存不存在则会触发后台SQL执行逻辑。 注:建立过连接的SQL将不需要用户名密码,可以任意填入。
- 缓存清除:清理当前该条的缓存。
- SQL分析:他是刷新缓存的依据,当flink感知到数据库变化后会触发一个数据事件,该数据事件会根据SQL分析结果来刷新缓存。
清理未使用的SQL记录:清理所有未勾选缓存的SQL记录,目的是为了批量清理无用的垃圾SQL记录
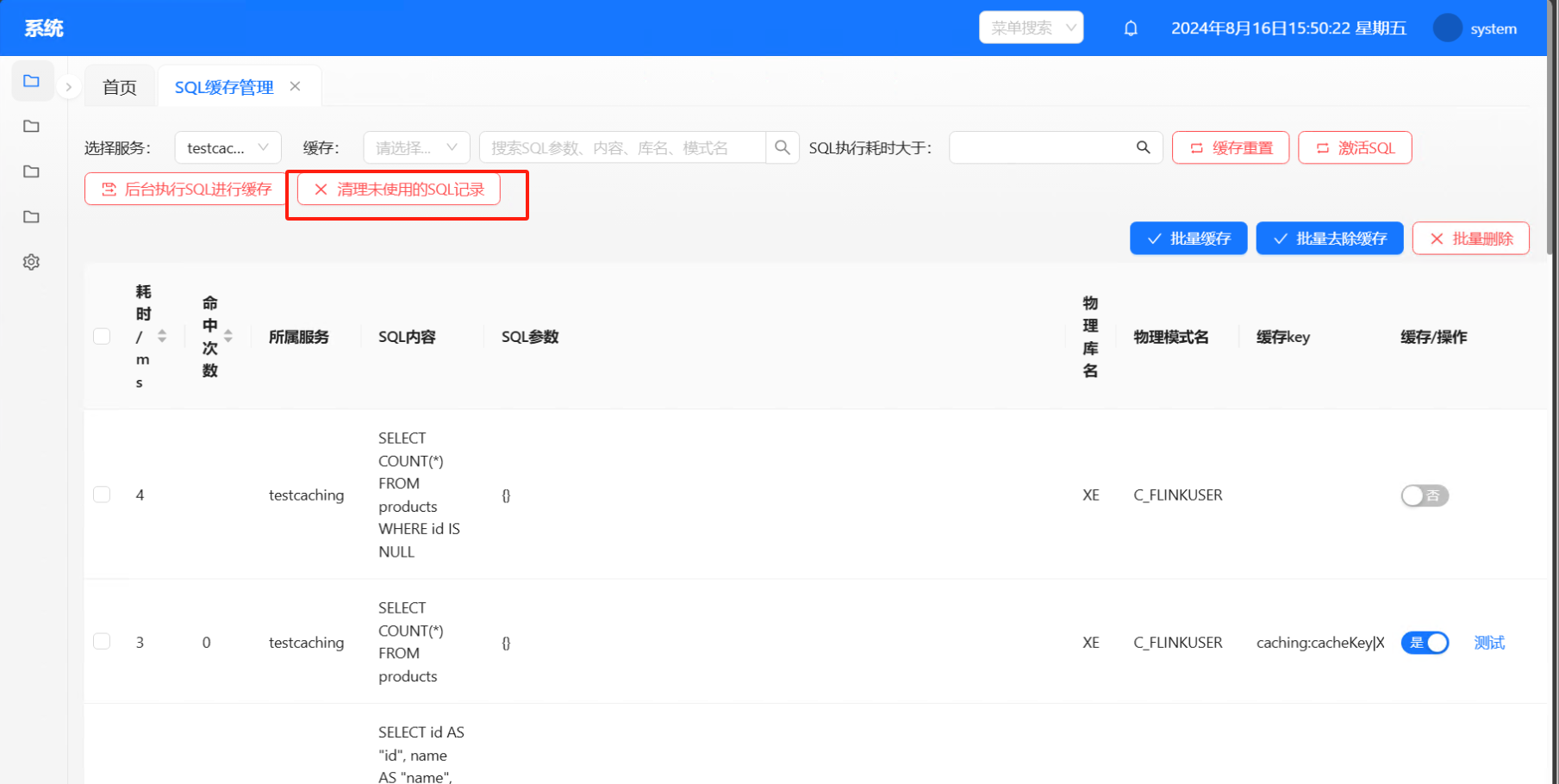
后台定时每天凌晨1点清理所有缓存:目的是为了解决缓存刷新发生异常后进行补偿动作(例如:flink整库同步发生不可抗因素异常,不能触发数据事件)
缓存中间件切换:平台会自动为SQL缓存服务分配rds,用户也可以自行定义配置不同的redis连接
- 如果是redis集群,多个地址需要用逗号隔开,如:
192.168.0.2:6379,192.168.0.3:6379,192.168.0.4:6379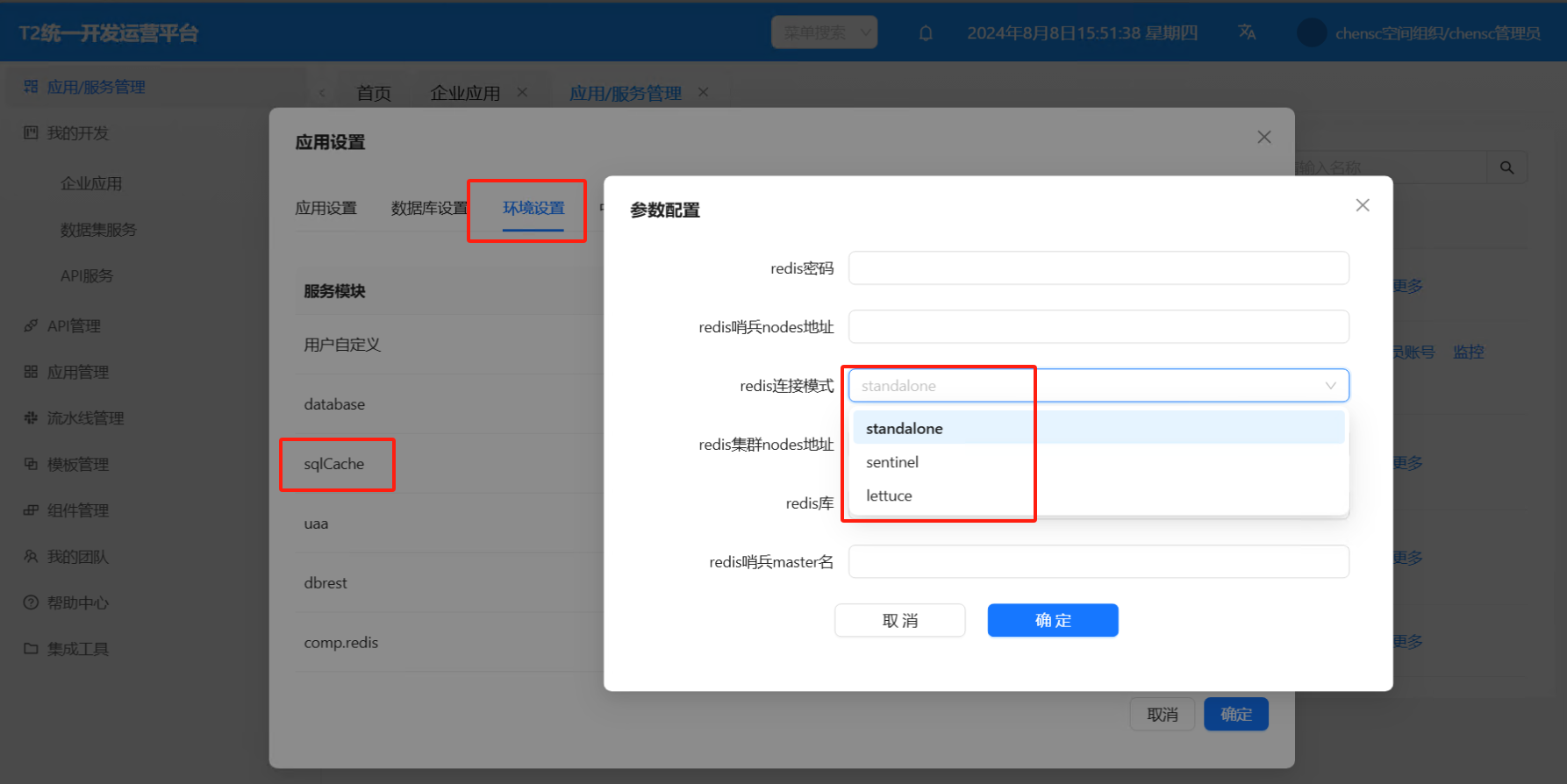
- 如果是redis集群,多个地址需要用逗号隔开,如: