sqlCache 概念和架构及原理
- 针对读多写少的表进行缓存
- 缓解数据库并发峰值
- 提高大SQL或慢SQL的查询效率
架构图
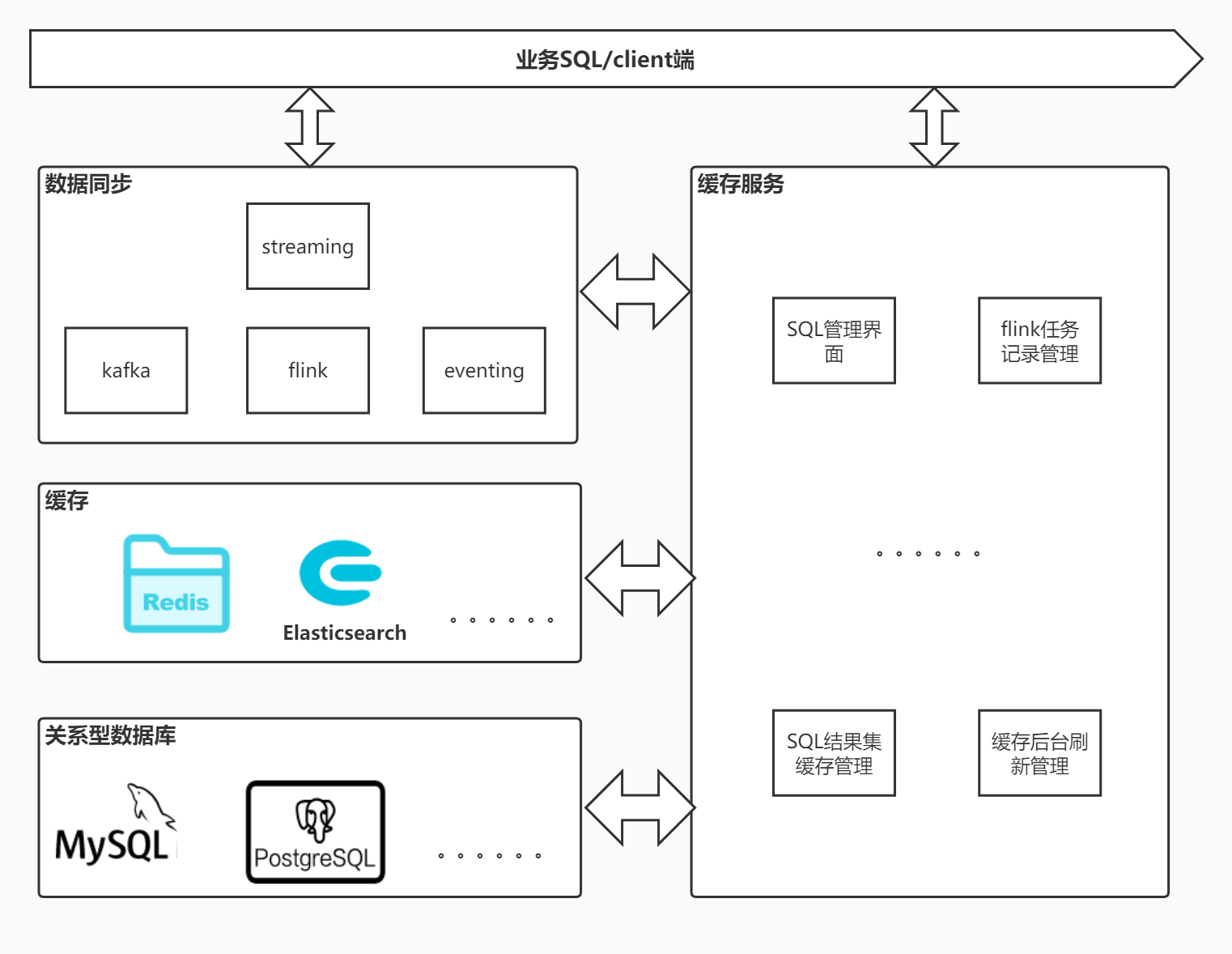
图例说明:
- SQL管理:主要职责是收集SQL、提供SQL管理界面
- flink任务记录管理: 用户自行勾选要同步的数据库以及表名,完成后进行flink任务提交到数据同步系统。这个过程需要记录下来进行可视化管理。
- SQL结果集缓存管理: 把SQL对应的结果集缓存提供client端
- 缓存后端刷新管理: 主要承载缓存刷新/失效策略逻辑
缓存实时刷新/失效的流程图
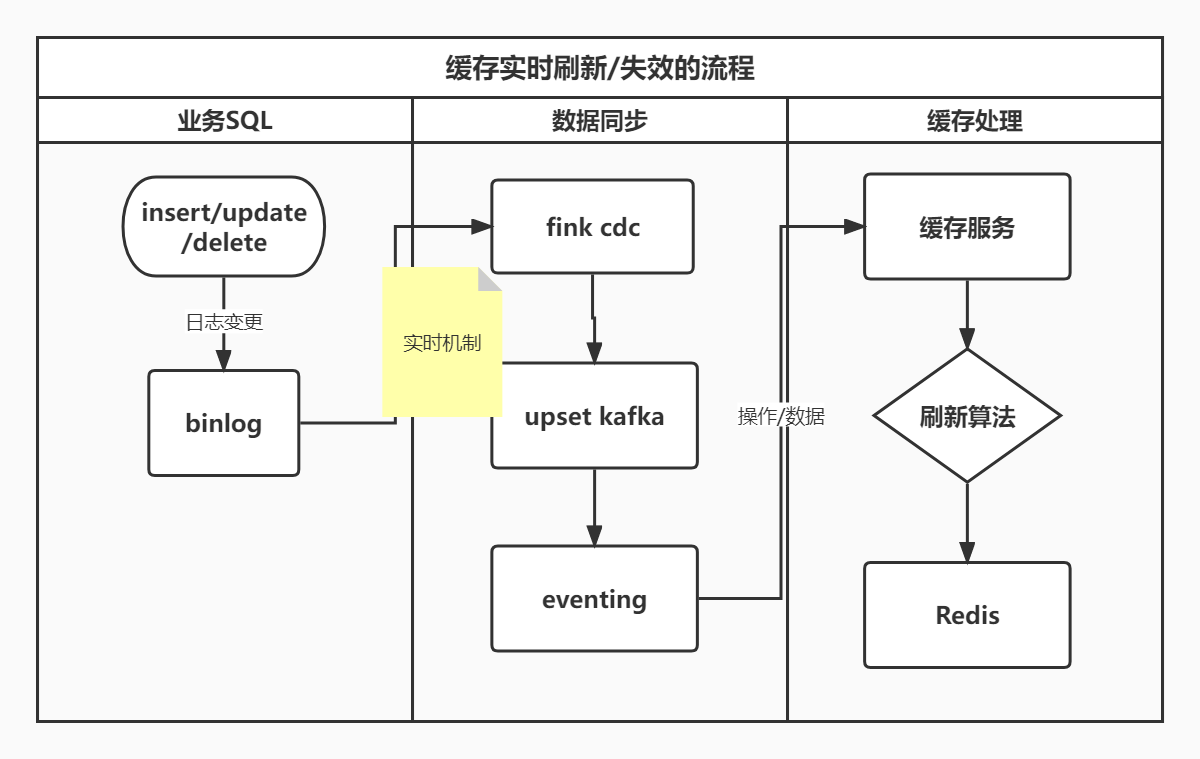
当用户勾选完SQL,缓存服务拿到勾选的SQL进行整体分析,然后:
- 第一步把勾选的SQL存入库作为元数据,
- 第二步生成缓存key,
- 第三步生成刷新缓存key的刷新key,
- 第四步存储SQL与缓存key的映射关系、和刷新key与缓存key的映射关系,
- 第五步调用Streaming服务启动dlink job,
SQL缓存服务内部后台的几个定时任务
- 激活SQL:后台有执行激活SQL的定时任务,会每隔1分钟定时执行一次,目的是对勾选缓存的SQL进行SQL分析,生成对应的缓存Key、刷新Key、event-trigger-cdc,和收集SQL时辅助使用到的Key,和命中次数刷库。
- 后台执行SQL进行缓存:定时每天凌晨2点执行一次,原理——》以队列的形式批量对勾选缓存的SQL进行执行,将结果覆盖到对应缓存Key上。这样即可以实现预先缓存的效果,大大减轻了缓存击穿和缓存刷新异常所带来的后果。
- 清理缓存:后台定时每天凌晨1点清理所有缓存:目的是为了解决缓存刷新发生异常后进行补偿动作(例如:flink整库同步发生不可抗因素异常,不能触发数据事件)。